最近在研究gRPC的客户端连接可用性的时候,测试了一个场景:gRPC的服务端主动断掉TCP连接之后,gRPC客户端持有的连接是否有效?步骤如下:
- 启动 gRPC 的客户端和服务端。
- gRPC 客户端向服务端发送一些数据(建立 TCP 连接,虽然 gRPC 是基于 http2,但是底层还是 TCP)。
- 杀死 gRPC 服务端,然后再快速成功拉起 gRPC 服务端。
- gRPC 客户端继续向 gRPC 服务端发送请求,是可以正常响应的(gRPC 客户端会自己维护连接的可用性)。
以上步骤,乍一看是没有问题的,但是想起 TCP 谁主动关闭连接,谁的连接状态就会变成 TIME_WAIT,TIME_WAIT 是需要 2MSL(linux 系统固定 60s)处于等待状态,期间服务端应该是不能使用同一个端口,也就是说应该不能立马拉起来的(与步骤 3 相矛盾)。
基于以上疑问,我对相关知识进行了一个梳理,一步步来解答上面的疑问。
TCP 为什么会有 TIME_WAIT 状态?
TCP 断开是通过四次挥手,这里需要记住客户端和服务端都可以主动断开连接,具体的过程如下: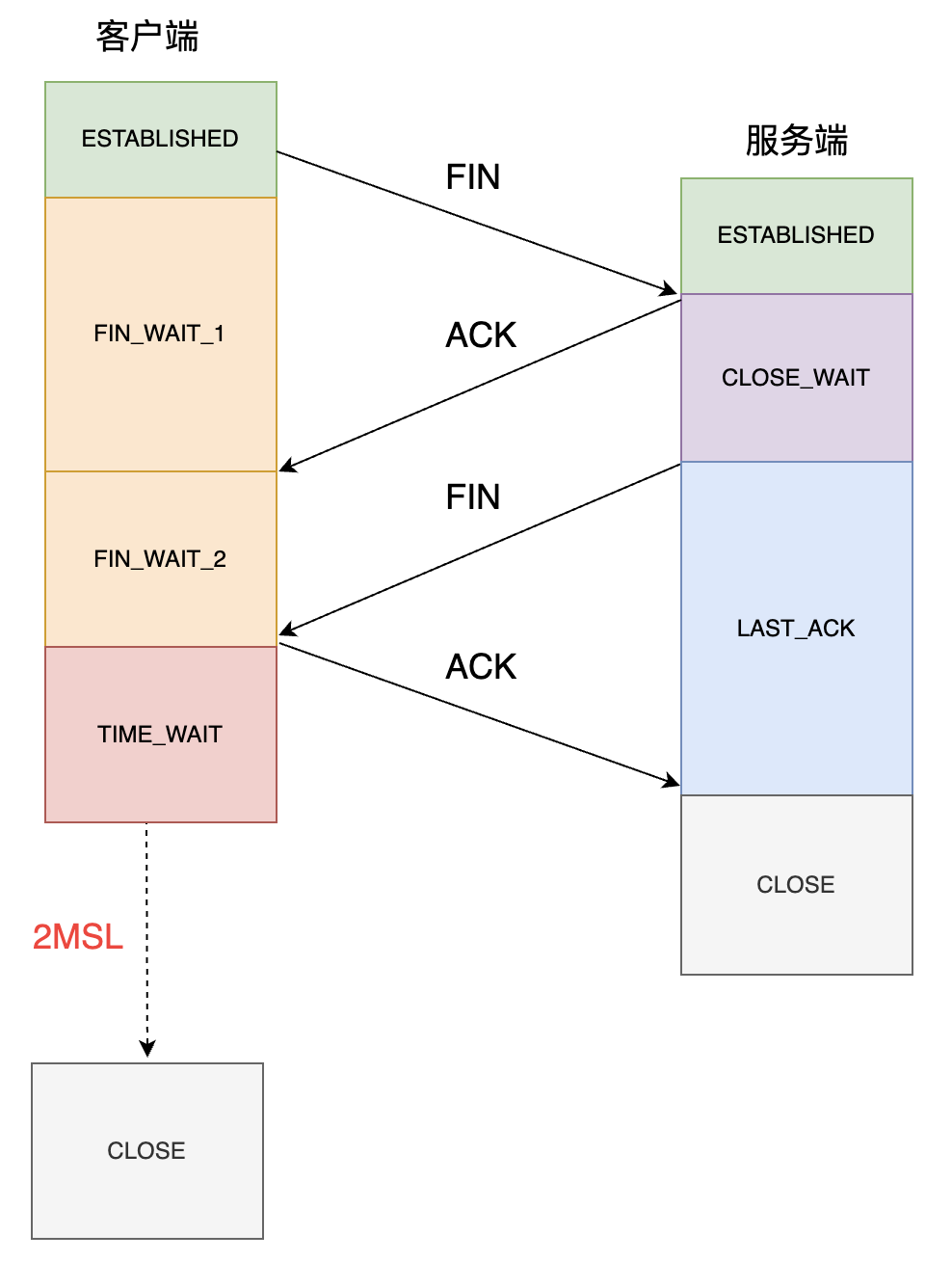
从上图可以看出,只要是主动关闭连接的一方,就会有TIME_WAIT状态。那为什么主动断开的一方需要保持TIME_WAIT状态呢?主要原因如下:
- 防止历史连接中的数据,被后面启动的相同端口的程序接收,造成数据混乱。
- 确保被动关闭连接的一方能够正常的关闭连接。
一、防止历史连接中的数据,被后面启动的相同端口的程序接收,造成数据混乱。
针对第一个原因,需要先明确两个知识点:
- TCP 是面向字节流的可靠协议,每次发送的报文段(segment)都有一个序列号,用来保证消息的顺序性和可靠性。
- TCP 的连接是通过五元组确认唯一性的,五元组为(源 IP,源端口,目标 IP,目标端口,协议/TCP or UDP)。
如果没有TIME_WAIT状态,在网络中延迟的数据包到达对端之后的情况如下: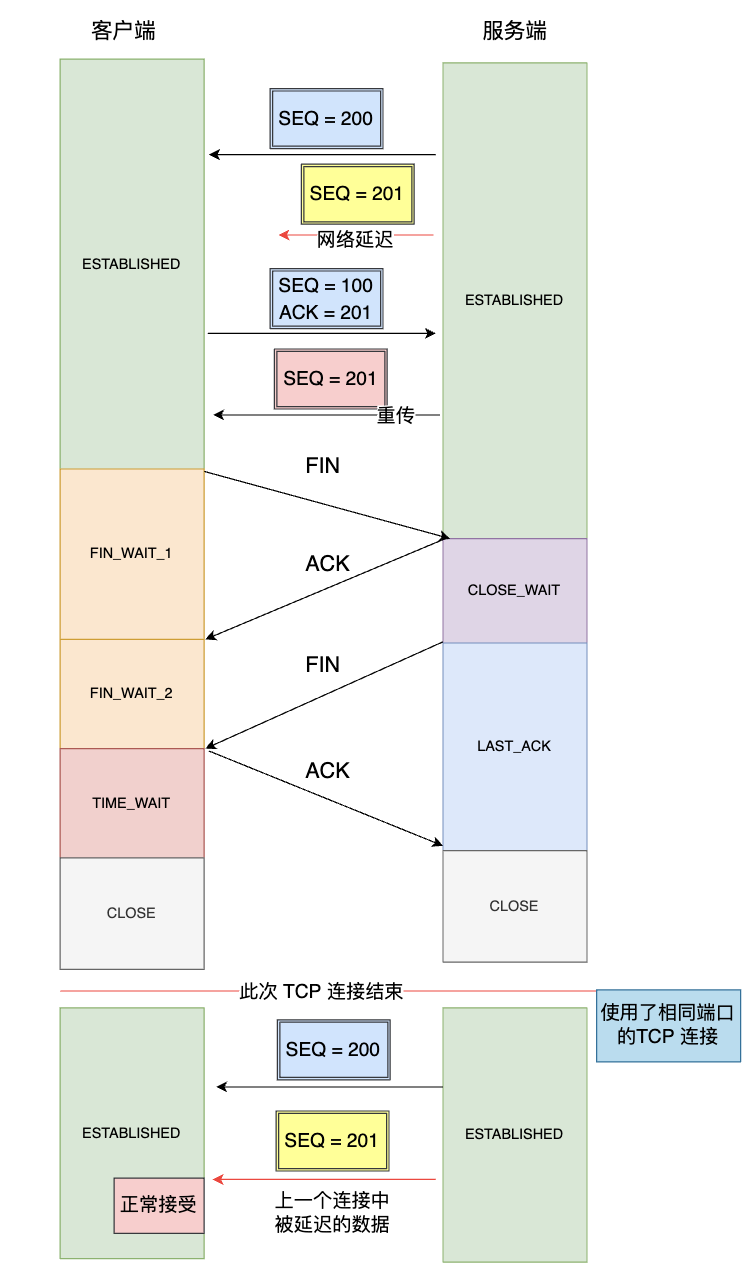
如上图所示:
- 服务端上一个连接中发送的一个 SEQ=200 的报文由于网络拥塞被延迟了。
- 结束了上一次连接后,客户端、服务端以相同的五元组建立了新的连接,之前被网络延迟的报文 SEQ= 200 刚好抵达了客户端,并且在客户端的接收窗口之内,因此会被客户端当作正常数据接收,但这个数据其实是上一个连接的数据,因此会造成数据错误的问题。
因此,为了防止以上情况的出现,TCP 设计TIME_WAIT状态,并让其持续 2MSL 的时长,这个持续的等待时间可以让两个方向上的报文都被丢弃,使得原来连接中的报文在网络中自然消亡,让旧连接上的报文没法影响新链接。
二、确保被动关闭连接的一方能够正常的关闭连接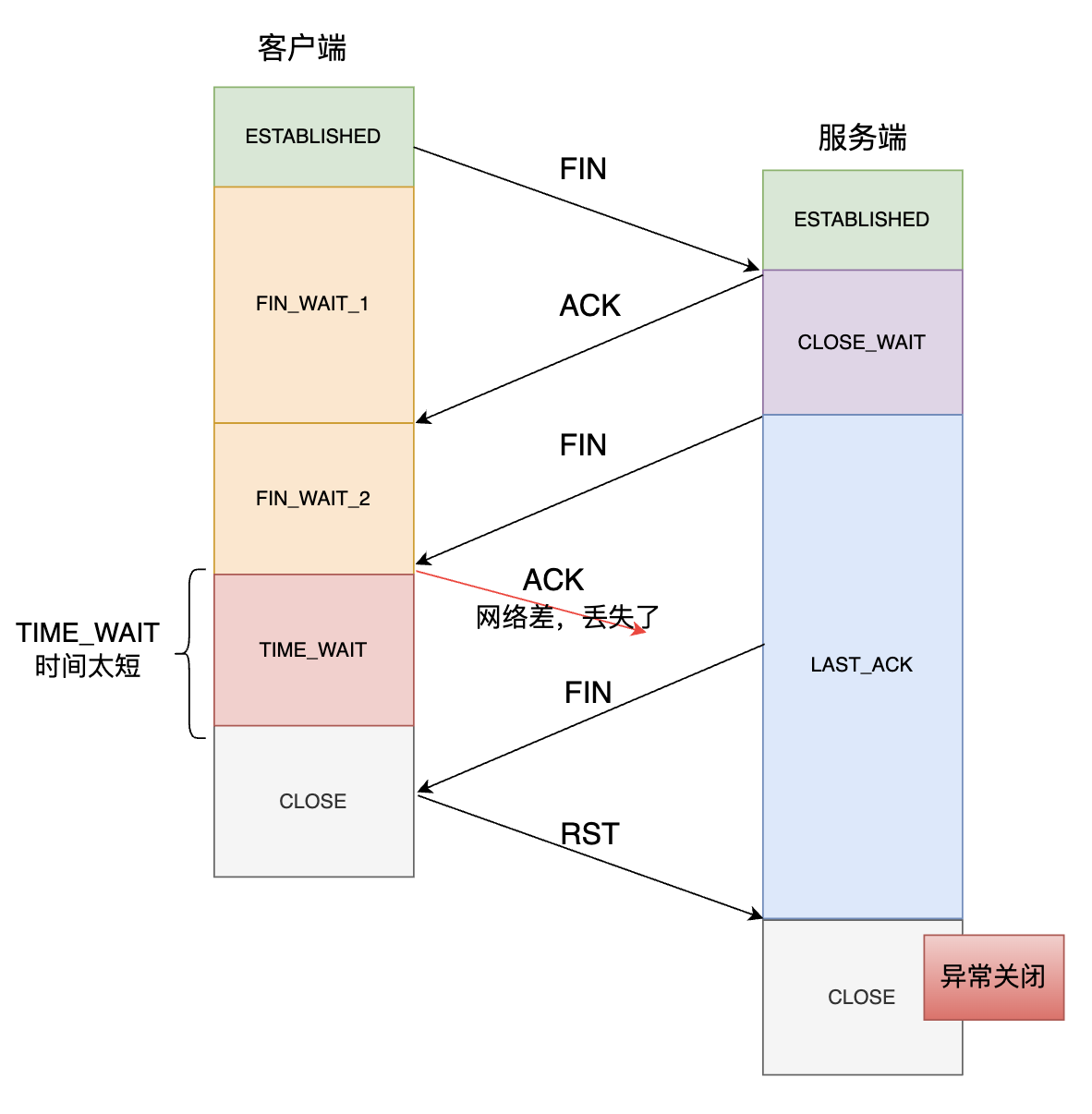
如上图所示,如果客户端(主动关闭方)最后一次 ACK 报文在网络中丢失了,那么按照 TCP 重传的规定,服务方(被动关闭方)会重发 FIN 报文。如果客户端 TIME_WAIT 的时间很短或者没有这个状态,那么重传的 FIN 报文到达客户端时,客户端已经处于 CLOSE 状态,就会回复一个 RST 报文,导致服务端异常关闭。
场景重现
一、启动 gRPC 的服务端和客户端,查看 TCP 连接状态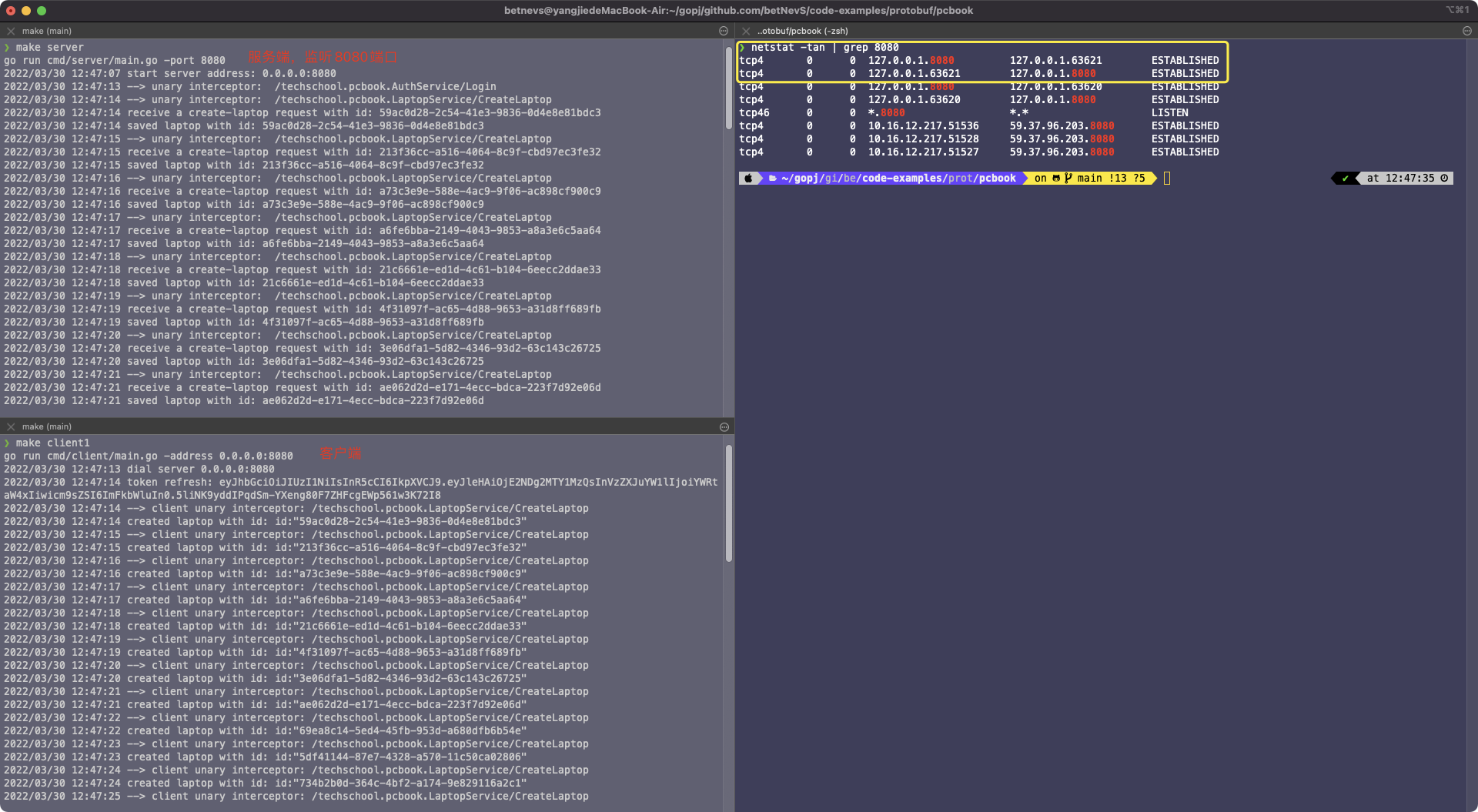
从上图可以分析可知:
- 客户端和服务端都在同一台机器,服务端监听 8080,客户端以端口 63621 与服务端通信
- 客户端的五元组为(127.0.0.1,63621,127.0.0.1,8080,TCP),服务端五元组为(127.0.0.1,8080,127.0.0.1,63621,TCP)
- 客户端和服务端的状态都是 ESTABLISHED
二、主动关闭服务端,查看 TCP 连接状态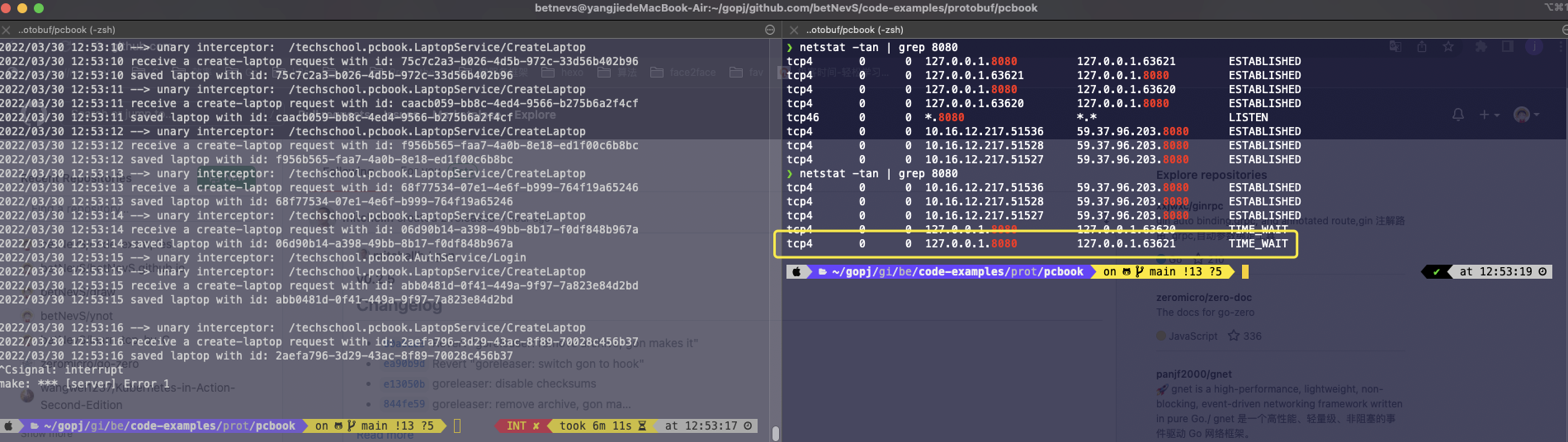
从上图分析可知:
- 主动关闭服务端,服务端五元组(127.0.0.1,8080,127.0.0.1,63621,TCP)处于了 TIME_WAIT 状态,之所以有两个 TIME_WAIT 是因为该 gRPC 客户端起了两个 TCP 连接,我们只关注其中一个即可。
三、重新启动服务端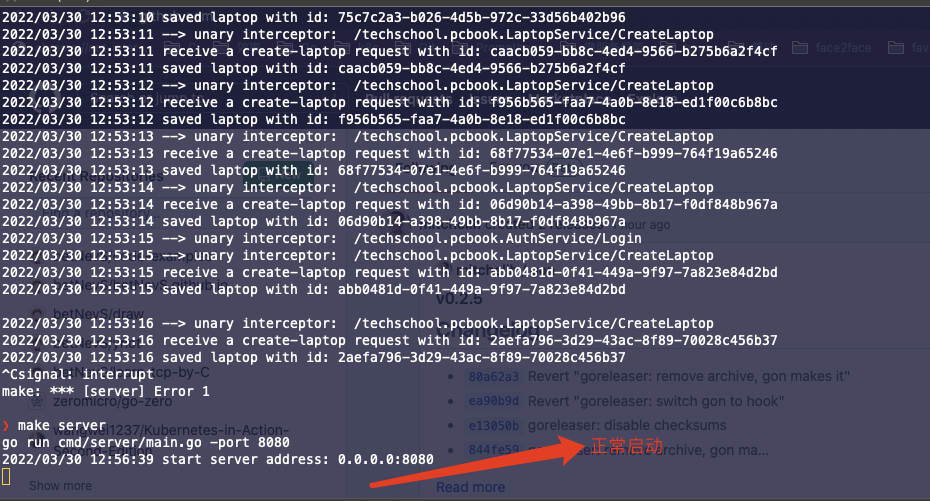
从上图分析可知:
- 立马重启服务端,没有异常,此处和我们上面讲的 TIME_WAIT 起码要维持 2MSL 的时间的结论不一致。为什么呢?
实验探究
从上面的现象盲猜一波,应该是 Go 的底层 TCP 库应该做什么操作,使得端口好像被复用了。
那我们用最原始的 C 语言来写个简单的服务端,模拟下上面的情况。代码如下:
1 | int main(int argc, char *argv[]) |
客户端用 Go 语言编写,代码如下:
1 | func main() { |
一、启动客户端和服务端,查看 TCP 连接状态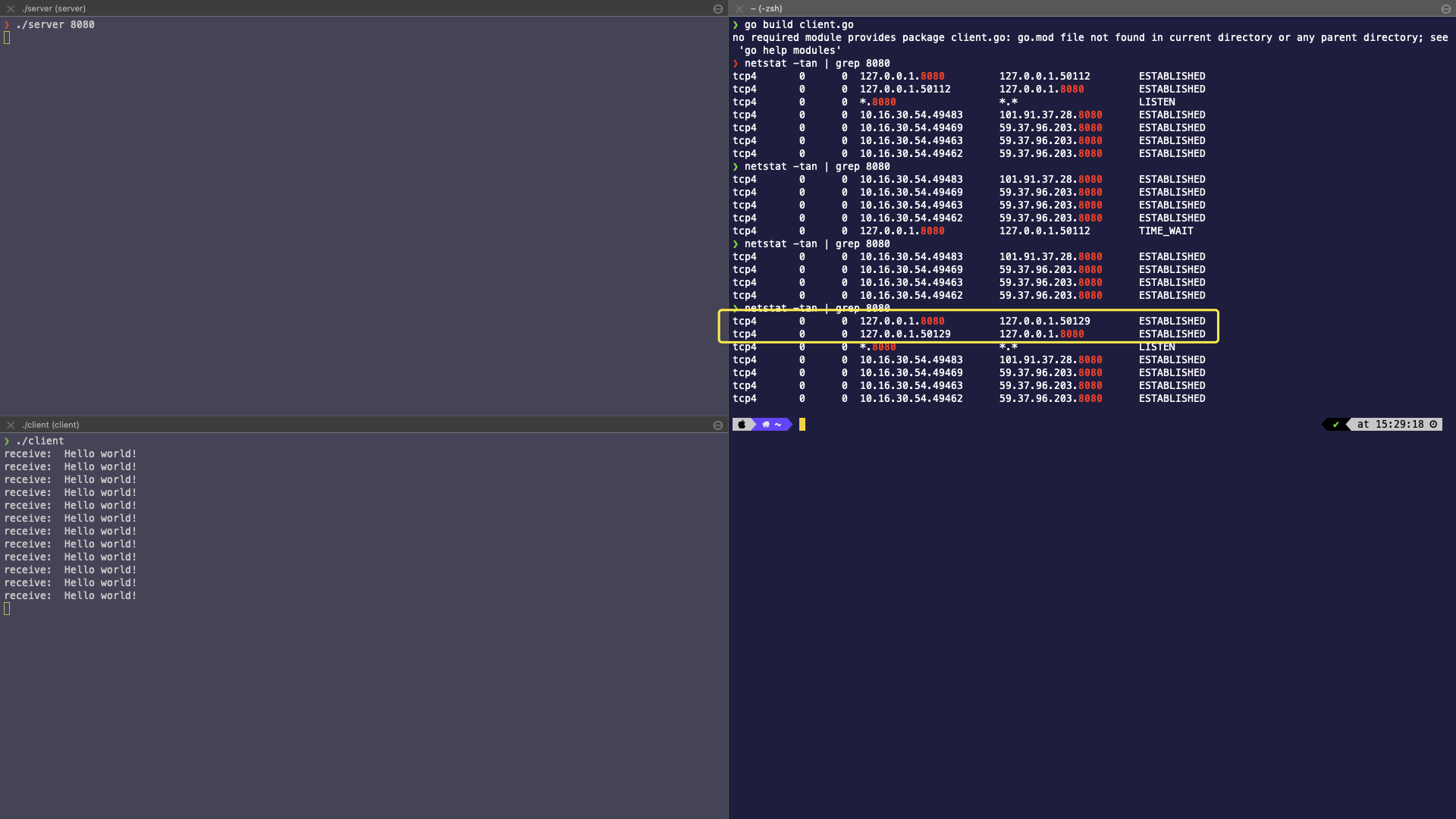
从上图可以分析可知:
- 客户端和服务端都在同一台机器,服务端监听 8080,客户端以端口 50129 与服务端通信。
二、手动关闭服务端,然后再启动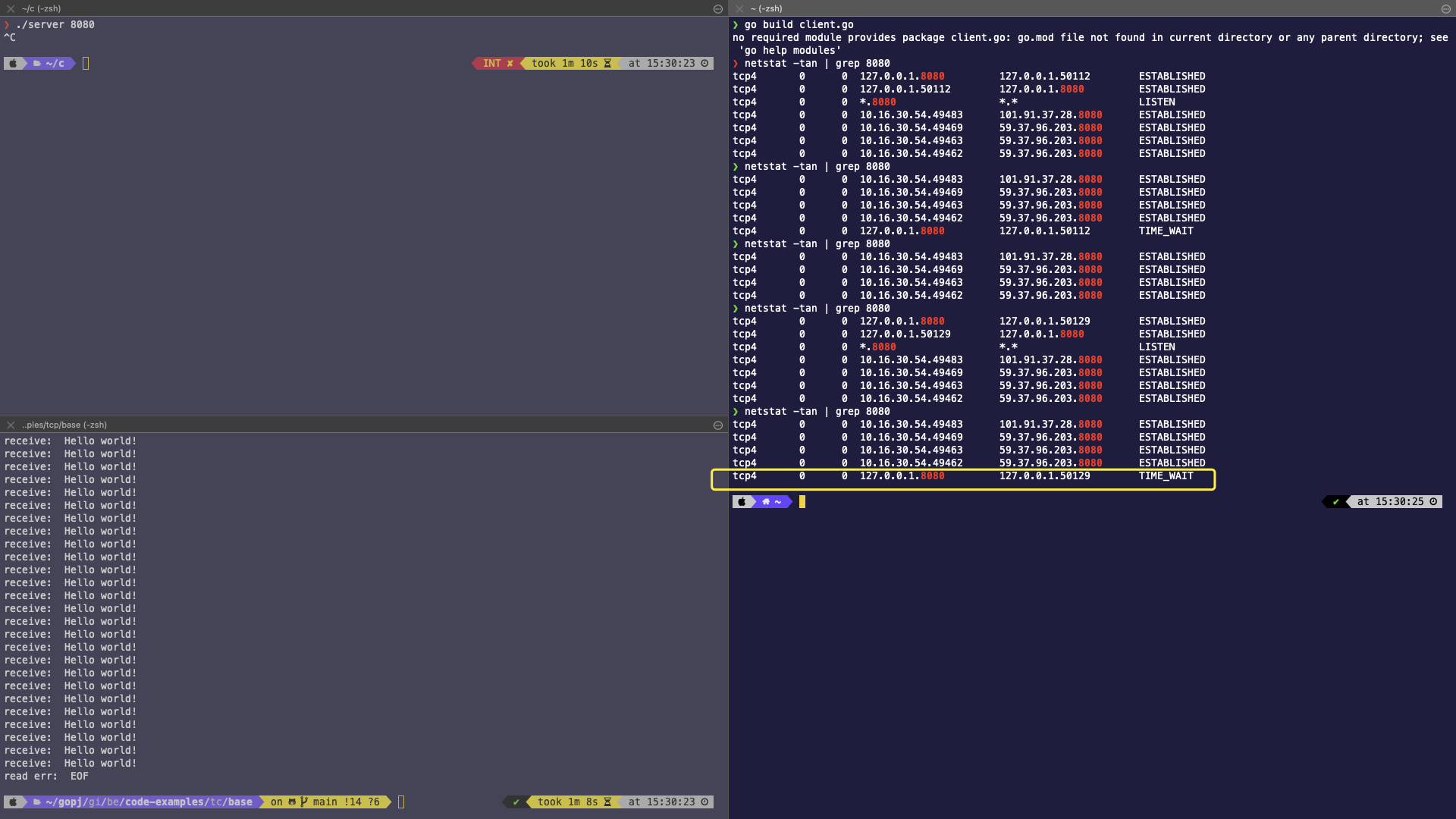
从上图分析可知:
- 主动关闭服务端,服务端五元组(127.0.0.1,8080,127.0.0.1,50129,TCP)处于了 TIME_WAIT 状态。
三、重启启动服务端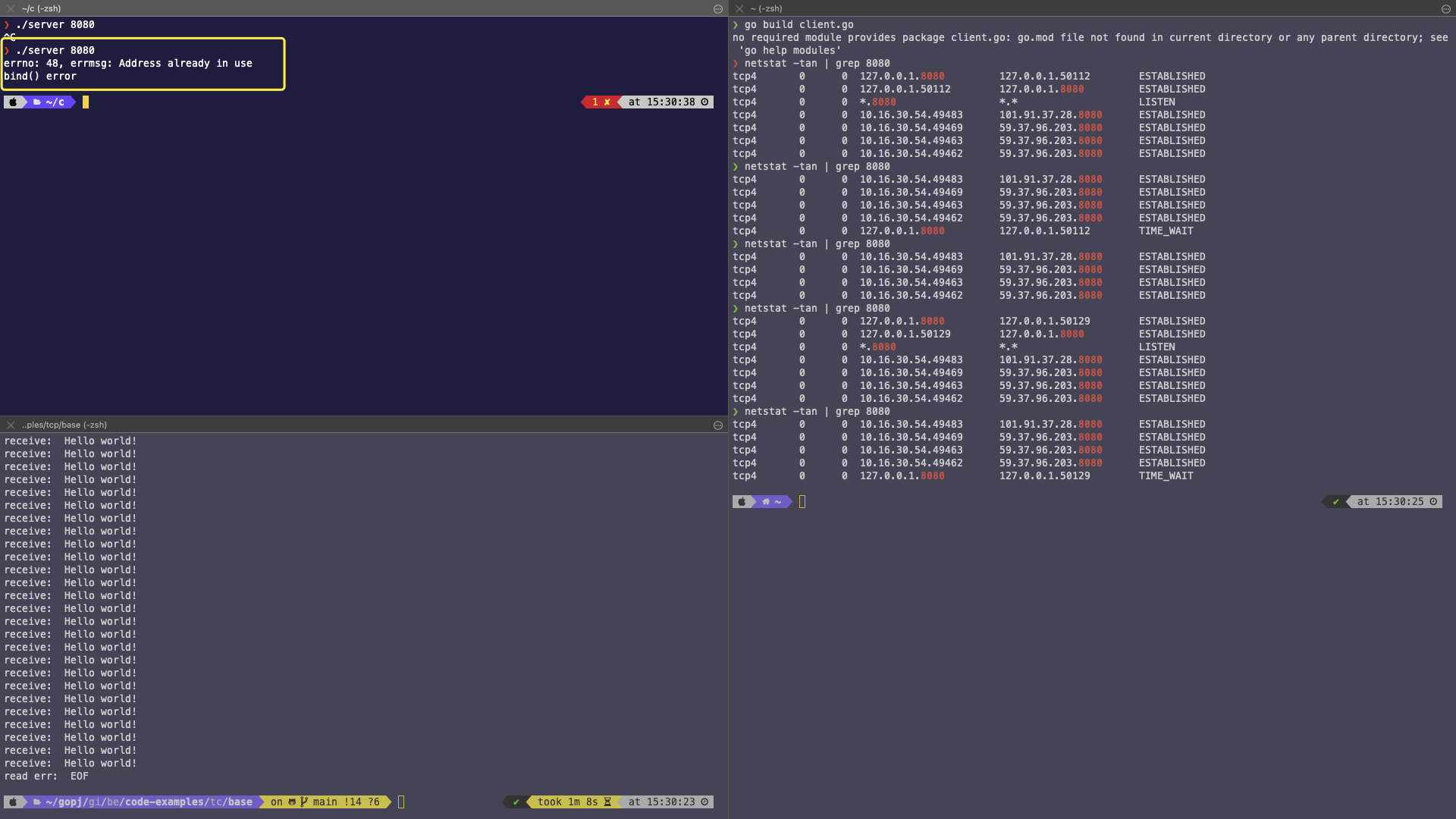
从上图分析可知:
- 重启服务端失败,显示错误
Address already in use,和我们之前回顾的 TCP TIME_WAIT 的现象吻合。
搜索了下相关资源,发现https://man7.org/linux/man-pages/man7/socket.7.html 中有提到:
在原来的代码中增加 SO_REUSEADDR 相关设置,代码如下:
1 | ................ |
增加完代码之后,重新启动客户端和服务端
然后主动关闭服务端,服务端出现 TIME_WAIT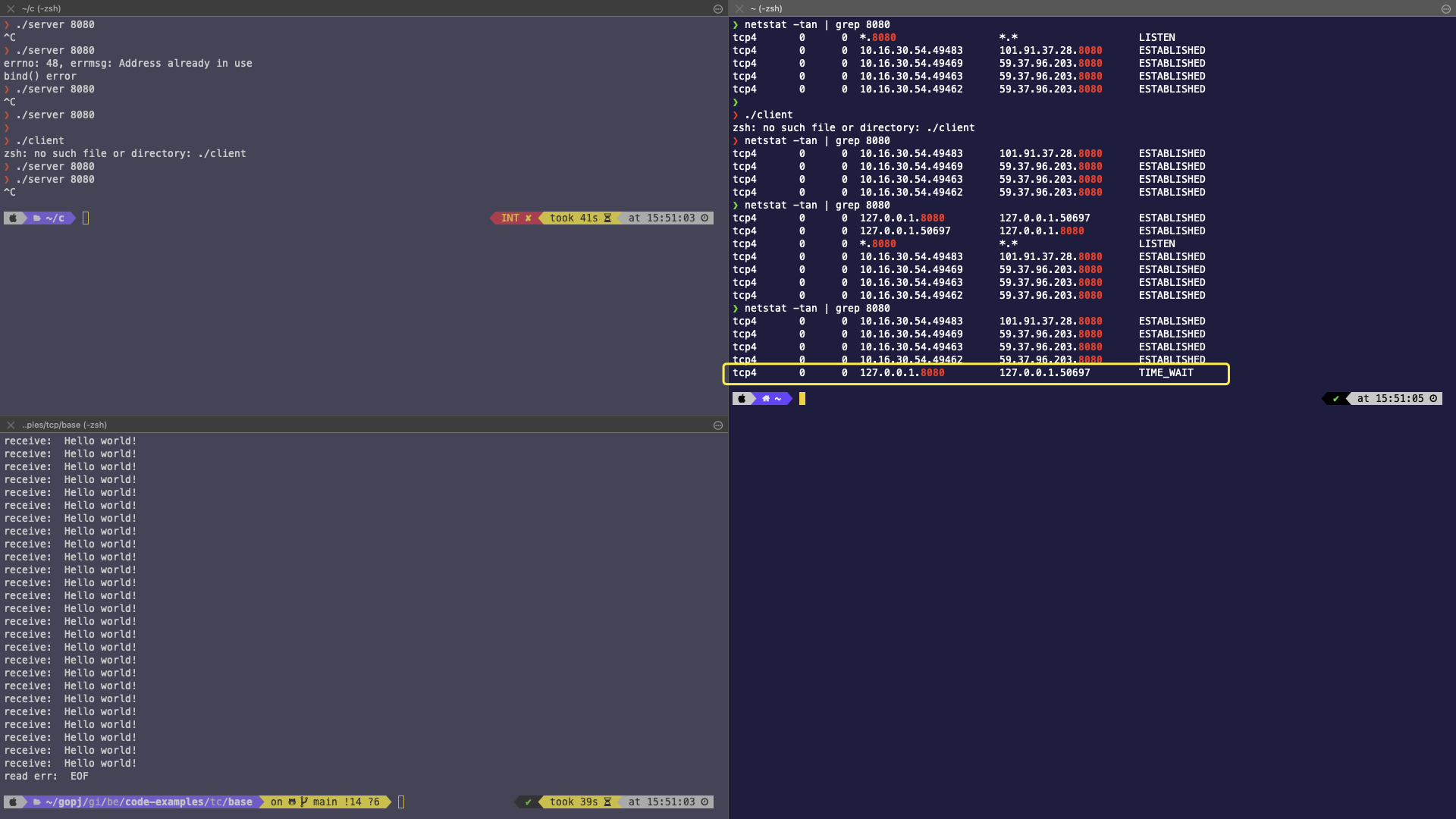
立马在启动服务端,没有出现错误,正常启动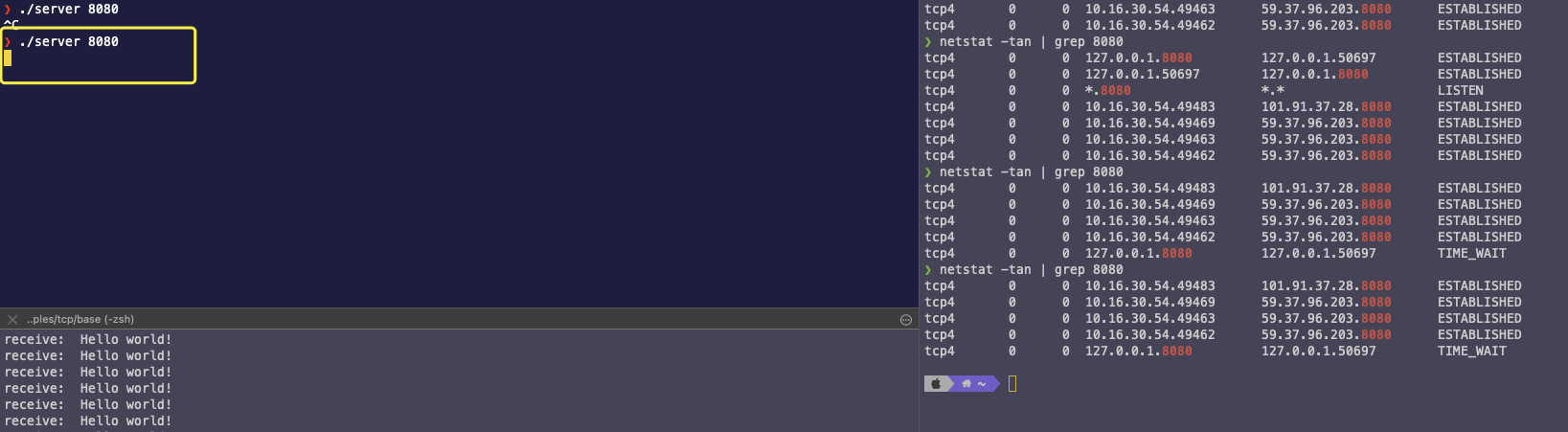
通过以上实验,我们可以猜测,Go 语言的底层 TCP 标准库,应该是默认设置了 OS_REUSEADDR,本着源码求知的原则,我去翻了下 Go 的源码,在路径 go/src/net/sockopt_linux.go 中找到了以下代码: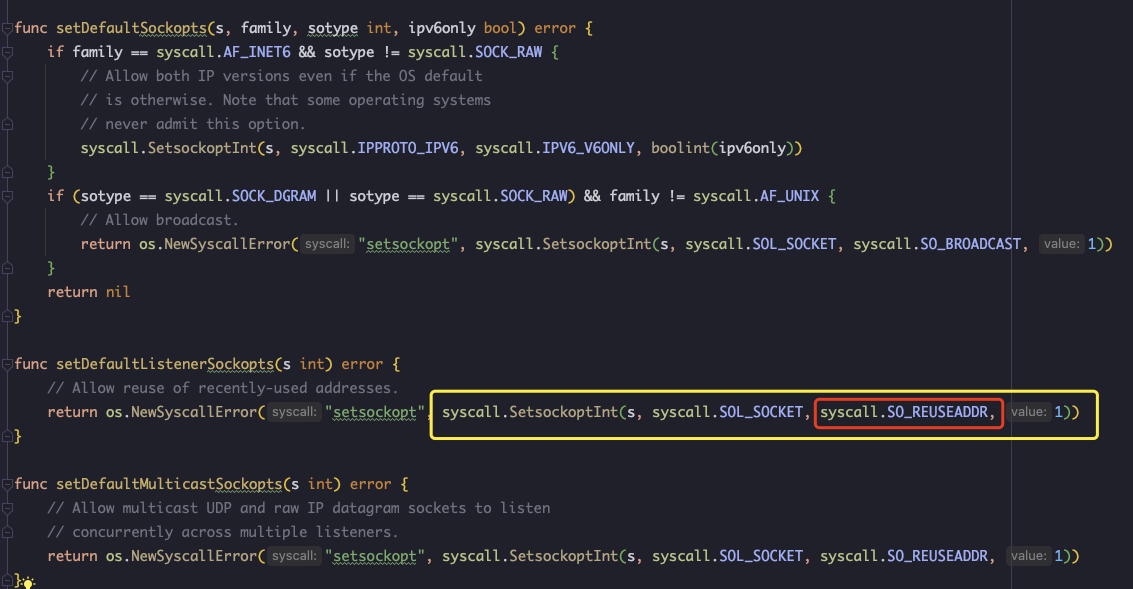
至此,真相大白,处处都是细节,本次求证也让我对 TCP 的四次挥手的状态有了更加深刻的理解。
总结
- TIME_WAIT 出现与主动断开连接的一方,客户端和服务端都是可以出现的。
- TIME_WAIT 设计是有自身道理的,不用过度通过各种配置去消除 TIME_WAIT,可以让客户端主动去断开连接,将 TIME_WAIT 分散到每个客户端上,而不是集中在服务端。
- 服务端通过在
bind前设置OS_REUSEADDR选项,让处于TIME_WAIT的端口可以被复用,这点是比较合理的,要不每次服务端重启都要间隔 60s 左右,使用体验会很差。 OS_REUSEADDR选项仅在服务端有效,并且只能使用于TIME_WAIT状态。也就是说,如果一个服务端正在正常端口,处理请求;此时再启动一个服务端监听相同的端口,是会出现Address already in use错误的,即使设置了OS_REUSEADDR。