前言 在 web 开发中,常常会遇到一个接口内依赖多个服务的情况,那必然会存在多次的接口调用,此时有串行调用和并发调用两种处理方式,来看下这两种方式的对比:
对比看出,并发调用的耗时取决于耗时最长的那个服务,整体耗时比串行调用减少了很多。熟悉 Go 的小伙伴立马会想到使用 goroutine 和 WaitGroup 来解决。但是在实际业务场景中,多个依赖中任何一个出现错误,我们期望的是立即返回,而不是等待所有的依赖执行完在返回结果。要想实现以上功能需要编排好并发任务,并且做好并发协程中的错误传递,这并不是个简单的事情,有很多细节要处理。归纳几个重点:
控制协程数量,当任务数太多时,不能一个任务起一个协程。
错误取消,在并发过程中,出现错误则取消所有任务,返回失败(使用者可选择不取消)。
防止协程泄漏。
针对以上场景,go-zero 提供了 MapReduce 并发控制工具,能够很好地进行并发任务的编排,下面先应用场景进行介绍,知道它的使用才能更好的了解它的设计思想。
应用场景
并发请求多个的接口,并对请求结果进行聚合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 func main () result := make (map [string ]string ) err := mr.Finish(func () error url := "https://www.baidu.com" res, err := requestUrl(url) if err != nil { return err } result[url] = string (res) return nil }, func () error url := "https://www.google.cn/" res, err := requestUrl(url) if err != nil { return err } result[url] = string (res) return nil }) if err != nil { log.Fatal(err) } fmt.Println(result) } func requestUrl (url string ) ([]byte , error) resp, err := http.Get(url) if err != nil { return nil , err } defer resp.Body.Close() return ioutil.ReadAll(resp.Body) }
以上代码,利用 MapReduce 中的 mr.Finish() 函数并发请求两个 url,并将返回值进行聚合到 result 的 map 中,如果其中一个并发请求出现错误返回,则取消所有任务,并直接返回结果,不需要等待所有任务返回,极大的提升了接口性能。
mr.Finish() 函数是基于 mr.MapReduce() 进行了一层封装,本质还是 MapReduce 。
并发处理数据,利用 MapReduce 的思想
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 func main () output, err := mr.MapReduce(func (source chan <- interface {}) for _, uid := range getUids() { source <- uid } }, func (item interface {}, writer mr.Writer, cancel func (error) ) uid := item.(int ) if checkUid(uid) { writer.Write(uid) } else { } }, func (pipe <-chan interface {}, writer mr.Writer, cancel func (error) ) uids := make ([]int , 0 ) for uid := range pipe { uids = append (uids, uid.(int )) } writer.Write(uids) }) if err != nil { log.Fatal(err) } fmt.Println(output) } func checkUid (uid int ) bool if uid > 99 { return false } return true } func getUids () []int return []int {1 ,2 ,3 ,4 ,5 ,100 ,9 } }
以上代码,并发请求接口 checkUid 校验 uid 是否合法,当在 map 和 reduce 操作中出现 error 时,使用者可以选择通过调用 cancel(error)函数取消所有并发的请求,立即返回结果。在 map 和 reduce 操作中利用 mr.Writer 实现通过 Go 中的 channel 传递数据。
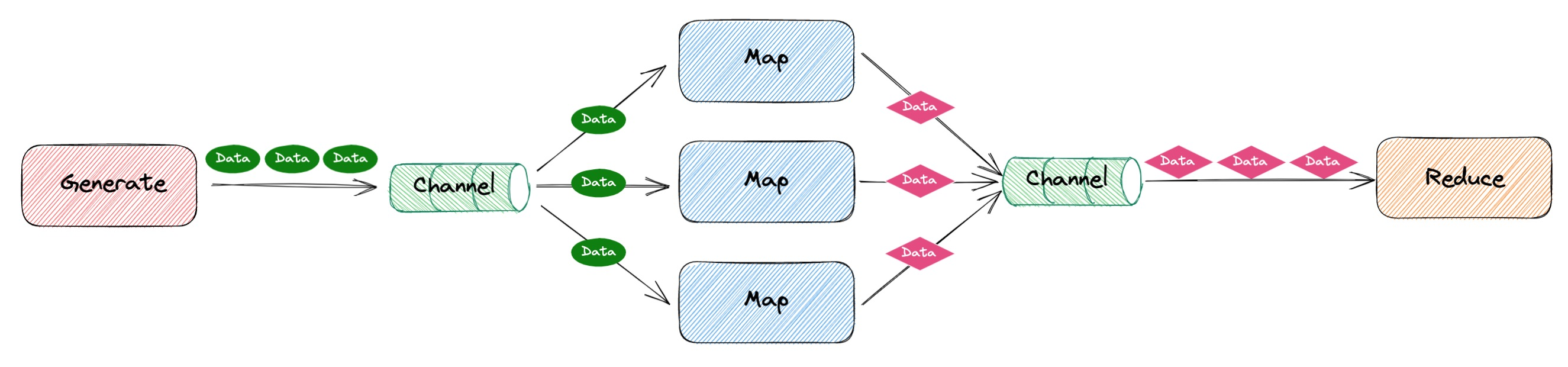
源码设计 MapReduce 代码结构
由上图可知,MapReduce 的代码结构主要由以下三个部分组成:
Generate 负责产生原数据,提供给 Map 进行处理Map 负责执行具体的业务逻辑处理,一般是多协程并发执行(数量由使用者自行定义)Reduce 负责将 Map 操作的结果进行聚合
接下来,我们将以上面三部分作为我们代码设计的目标。
Generate 代码设计 Generate 是为了产生原始数据,然后将数据写入通道中,提供给 Map 进行处理,结构如下:
根据上面的功能描述,我们的设计目标是:
提供一个函数让使用者写原始数据产生的逻辑
提供一个通道让使用者写入数据
将目标 1,2 中的逻辑封装在一起,并且将目标 2 中的通道提供给 Map 部分的代码使用
针对目标 1,我们可以定义一个函数变量 GenerateFunc func(source chan<- interface{}) ,使用者只需在 GenerateFunc 中实现自己产生原始数据的逻辑,然后将数据写入通道 source 中,目标 1 就完成了。
针对目标 2,使用者只负责写入数据,不会去维护一个通道的,因此目标 1 中的通道 source 需要代码设计者自己维护,为了保证通用性,因此定义通道 source 为 source := make(chan interface{}) 。
针对目标 3,我们封装一个函数 func buildSource(generate GenerateFunc) chan interface{} ,接收使用者实现的写入原始数据的逻辑,然后将提供通道给 Map 部分的代码使用。
我们可以得到初始代码如下:
1 2 3 4 5 6 7 8 func buildSource (generate GenerateFunc) chan interface source := make (chan interface {}) go func () generate(source) close (source) }() return source }
以上代码在功能上已经满足了我们的设计目标,但是作为代码的设计者需要为使用者思考的更多些,由于以上第 4 行的代码generate() 是由使用者去实现里面的具体逻辑,可能会出现 panic 的情况,如果没有进行 recover() 则会导致整个进程的退出,因此设计者需要替使用者着想,优化代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 func buildSource (generate GenerateFunc) chan interface source := make (chan interface {}) go func () defer func () if err := recover (); err != nil { log.Println(err) } }() generate(source) close (source) }() return source }
但还有一个不完美的地方,就是以上代码的第 11 行,如果第 10 行代码 generate() 出现 panic ,是不会执行到第 11 行的 close(source) ,导致通道 source 的使用者感知不到通道已经关闭了,容易导致阻塞和协程泄漏的问题。因此可以通过 defer 优化下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 func buildSource (generate GenerateFunc) chan interface source := make (chan interface {}) go func () defer func () if err := recover (); err != nil { log.Println(err) } }() defer close (source) generate(source) }() return source }
在使用通道的时候一定要遵守,谁写入谁关闭,谁接收谁消费殆尽,否则很容易出现协程泄漏的问题。殆尽,这个词很重要,后面会讲为什么。
recover() 只能捕获同一个协程中的中 panic ,并不能捕获子协程中的 panic 。由于函数 generate() 是由使用者实现的,为了防止其中出现 panic 导致整个程序的退出,代码的设计者在这里进行了兜底,但如果在函数 generate() 中 又用 go func(){}() 另起一个协程,并且其中出现了 panic ,那就兜底不了,整个程序会退出,这对于 web 这种常驻服务来说是不能接受的,所以要小心再小心。
为了避免协程 panic ,go-zero 专门封装了一个安全启动协程的代码,具体实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 func GoSafe (fn func () ) go RunSafe(fn) } func RunSafe (fn func () ) defer rescue.Recover() fn() } func Recover (cleanups ...func () ) for _, cleanup := range cleanups { cleanup() } if p := recover (); p != nil { logx.ErrorStack(p) } }
至此,Generate 部分就设计完毕了,接下来我们进入 Map 部分的设计。
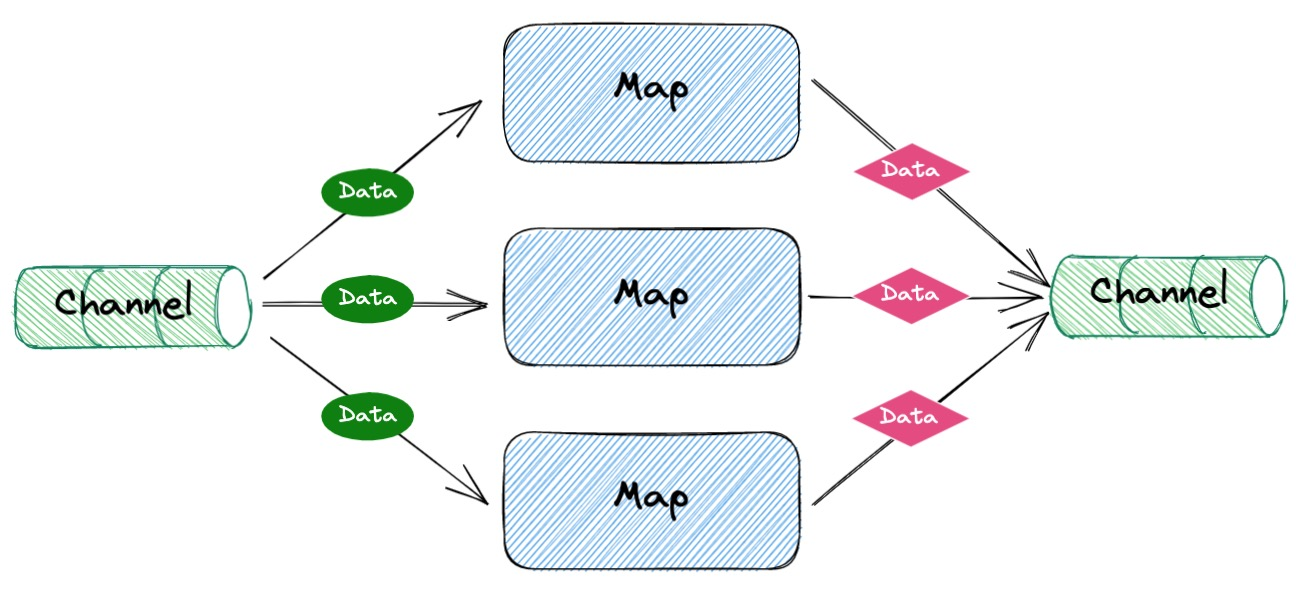
Map 代码设计 Map 部分是从通道中读取数据,然后执行 Map 操作的具体逻辑,最后写入另一个通道,提供给 Reduce 使用。
根据上面的功能描述,我们的设计目标是:
提供一个函数让使用者写具体执行的 map 逻辑
提供一个通道让使用者写入执行完 map 逻辑之后的数据,提供给 Reduce 使用
并发执行 map 逻辑,并发协程数量可控
针对目标 1、2,我们定义一个函数变量 MapFunc func(item interface{}, collector chan<- interface{}) ,使用者只需在 MapFunc 中实现自己的 map 逻辑,然后将数据写入通道 collector 中就完成任务。
针对目标 3,我们利用 go func(){}() 就能轻易执行并发逻辑,那么如何控制并发数量呢?此处我们先定义一个变量 works int 表示需要控制的协程数量,然后控制并发协程数量可以理解成超过使用者设定数量的协程就阻塞,等前面的协程运行完再轮到后面阻塞的协程 。基于以上理解,我们可以利用 Go 的带缓存通道,定义一个变量pool := make(chan struct{}, workers),此处使用空结构体 struct{} 代表只是为了占位,并不是为了传输数据,能够向通道 pool 写入数据,则表示允许启动一个协程运行任务,当通道中的缓存满了,则向通道写入数据会阻塞,表示目前已经达到可运行协程数量上限,需等待前面的协程运行结束。
基于以上目标,我们可以定义一个控制执行所有 map 逻辑的函数 func executeMappers(mapper MapFunc, input <-chan interface{}, collecter chan<- interface{}, workers int) ,初始代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 func executeMappers (mapper MapFunc, input <-chan interface {}, collector chan <- interface {}, workers int ) pool := make (chan struct {}, workers) var wg sync.WaitGroup defer func () wg.Wait() close (collector) }() for { select { case pool<- struct {}{}: item, ok := <-input if !ok { <-pool return } wg.Add(1 ) go func () defer func () wg.Done() <-pool }() mapper(item, collector) }() } } }
executeMappers 函数相当于整个 map 操作部分的管理者,从以上代码第 8 行到第 26 行,就是一个 for 循环不断从通道 input 中读取数据(第 11 行),然后启动协程去执行使用者定义的map 操作(第 23 行),当 input 被关闭之后就退出 for 循环(第 11-15 行),等待所有并发的协程执行完毕则关闭通道 collector(第 4-7 行)。
以上代码实现了基本功能,但是有两个地方不够完美:
和之前一样 mapper 函数是由使用者实现逻辑,可能出现 panic ,代码设计者要帮忙 recover
如果 map 操作中出现错误,使用者可以通过取消操作停止所有的 map 操作
针对 1,我们使用上面封装好的 GoSafe 函数即可解决。针对 2,需要先明白停止所有的 map 操作需要做什么事情,一个是退出 executeMappers 函数中的 for 循环,一个是 mapper 函数中停止向通道 collector 写入数据。在 Go 语言中,我们通常会采用 close 一个通道来达到广播通知 的效果,因此我们需要再定义一个通道 done <-chan struct{} ,因此优化后的代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 func executeMappers (mapper MapFunc, input <-chan interface {}, collector chan <- interface {}, workers int , done <-chan struct {}) pool := make (chan struct {}, workers) var wg sync.WaitGroup defer func () wg.Wait() close (collector) }() for { select { case <-done: return case pool<- struct {}{}: item, ok := <-input if !ok { <-pool return } wg.Add(1 ) threading.GoSafe(func () defer func () wg.Done() <-pool }() mapper(item, collector, done) }) } } }
以上代码对于使用者来说增加了编码的工作,因为之前只需要在代码中将执行 map 逻辑的数据写入通道 collector ,现在还需要增加一个判断逻辑,伪代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func mapper (item interface {}, collector chan <- interface {}) newdata := dofunc(item) collector <- newdata } func mapper (item interface {}, collector chan <- interface {}, done <-chan struct {}) newdata := dofunc(item) select { case <-done: return default : collector <- newdata } }
对比两者,对于使用者来说还是增加了一定的负担,而且代码也不够好看,有没有办法代码的设计者帮使用者解决这个问题呢?
我们可以将 collector chan<- interface{} 和 done <-chan struct{} 进行组合,替使用者做完退出时候要做的判断。通过定义一个接口类型并实现一个 Write 方法,具体实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 type ( Writer interface { Write(v interface {}) } ) type guardedWriter struct { channel chan <- interface {} done <-chan struct {} } func newGuardedWriter (channel chan <- interface {}, done <-chan struct {}) guardedWriter return guardedWriter{ channel: channel, done: done, } } func (gw guardedWriter) Write (v interface {}) select { case <-gw.done: return default : gw.channel <- v } }
通过 guardedWriter 我们的代码得到进一步优化,完整版如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 func executeMappers (mapper MapFunc, input <-chan interface {}, collector chan <- interface {}, done <-chan struct {}, workers int ) var wg sync.WaitGroup defer func () wg.Wait() close (collector) }() pool := make (chan lang.PlaceholderType, workers) writer := newGuardedWriter(collector, done) for { select { case <-done: return case pool <- lang.Placeholder: item, ok := <-input if !ok { <-pool return } wg.Add(1 ) threading.GoSafe(func () defer func () wg.Done() <-pool }() mapper(item, writer) }) } }
而对于使用者来说,代码得到了精简:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func mapper (item interface {}, collector chan <- interface {}, done <-chan struct {}) newdata := dofunc(item) select { case <-done: return default : collector <- newdata } } func mapper (item interface {}, writer Writer) newdata := dofunc(item) writer.Write(newdata) }
至此,Map 部分的代码也分析完了,满满的细节,接下来进行 Reduce 部分的代码设计。
Reduce 代码设计 Reduce 部分是从通道 collector 中读取数据,然后进行聚合,最终返回输出给使用者。
根据上面的功能描述,我们的设计目标是:
提供一个函数让使用者写具体执行的 reduce 逻辑
提供一个通道让使用者将执行完 reduce 逻辑之后的聚合数据输出
根据之前的经验,我们可以定义一个函数变量 ReducerFunc func(collector <-chan interface{}, writer Writer),提供给使用者写 reduce 的逻辑代码,因此得到初始代码:
1 2 3 go func () reducer(collector, writer) }()
而对于使用者来说,代码可以这样写:
1 2 3 4 5 6 7 func reducer (collector <-chan interface {}, writer Writer) var res []interface {} for t := range collector { res = append (res, t) } writer.Write(res) }
与之前 map 部分类似,reduce 也是提供给使用者实现的,那么也可能出现 panic ,但是与 map 部分在 recover 之后的处理方式是不同的,之前 map 部分在 recover 是直接打印一个日志,因为是多任务并发执行,其中一个出错不会对我们总体的聚合结果造成太大影响,只需要记录日志。但是,最后一步 reduce 出错,是需要终止整个 mapreducer 操作,并将错误返回给使用者的。此处先记住我们需要一个 cancel 函数去应对异常情况。
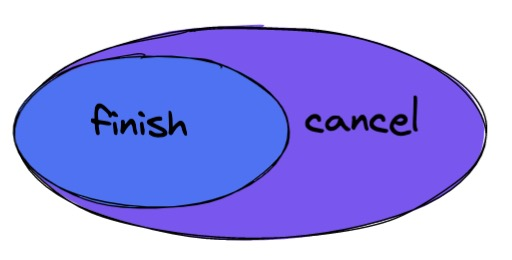
cancel 函数设计 MapReduce 是一系列流式的操作,肯定会涉及到出错时要怎么取消的问题?其实,取消(cancel)和 结束(finish)是一个包含和被包含的关系,因为结束的操作一般是回收资源,取消是处理异常并且回收资源,它们的关系如下:
由上文可知,MapReduce 使用了很多 Go 的通道,因此处理 取消(cancel) 就不得不先讨论下 通道 的处理。由于通道阻塞的特性在使用过程中,很容易出现协程泄漏的问题,那什么是协程泄漏呢?
启动的协程没有按照预期退出,直到程序结束,协程才退出,这就是协程泄漏。当出现协程泄漏,该协程的栈一直被占用不能释放,协程在堆上申请的空间也不能被垃圾回收器回收,因此在程序运行期间,内存占用持续升高,可用内存越来越少,最终导致程序崩溃。
一个简化版的 mapreduce 代码,处理并发处理一批数据,将每个数+100,然后打印结果数组,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 func main () source := make (chan int ) collector := make (chan int ) var res []int go func () defer fmt.Println("generate end" ) arr := []int {1 , 2 , 3 , 4 , 5 } for _, v := range arr { source <- v } }() go func () defer fmt.Println("map end" ) for v := range source { go func (item int ) collector <- item + 100 }(v) } }() go func () defer fmt.Println("reduce end" ) for v := range collector { res = append (res, v) } }() for { fmt.Println("result:" , res, ", goroutine num:" , runtime.NumGoroutine()) time.Sleep(time.Second) } }
运行结果:
1 2 3 4 5 6 7 8 9 result: [] , goroutine num: 4 generate end result: [101 103 102 105 104] , goroutine num: 3 result: [101 103 102 105 104] , goroutine num: 3 result: [101 103 102 105 104] , goroutine num: 3 result: [101 103 102 105 104] , goroutine num: 3 ......... ......... .........
从上可知,一开始有 4 个协程:generate 协程,map 协程,reduce 协程,main 主协程,然后 generate 协程将数据写入完毕结束了,但是 map 协程和 reduce 协程却一直阻塞,没办法结束,这样就造成了这两个协程的泄漏。
map 协程阻塞在了代码 16 行,reduce 协程阻塞在代码 25 行。
那如何解决这个问题呢?其实很简单就是一句话:谁写入谁关闭,关闭之后 for range 就会结束,不会阻塞着。修改代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 func main () source := make (chan int ) collector := make (chan int ) var res []int go func () defer fmt.Println("generate end" ) defer close (source) arr := []int {1 , 2 , 3 , 4 , 5 } for _, v := range arr { source <- v } }() go func () defer fmt.Println("map end" ) var wg sync.WaitGroup for v := range source { wg.Add(1 ) go func (item int ) defer wg.Done() collector <- item + 100 }(v) } wg.Wait() close (collector) }() go func () defer fmt.Println("reduce end" ) for v := range collector { res = append (res, v) } }() for { fmt.Println("result:" , res, ", goroutine num:" , runtime.NumGoroutine()) time.Sleep(time.Second) } }
运行结果:
1 2 3 4 5 6 7 8 9 10 result: [] , goroutine num: 4 map end generate end reduce end result: [101 102 103 105 104] , goroutine num: 1 result: [101 102 103 105 104] , goroutine num: 1 result: [101 102 103 105 104] , goroutine num: 1 ......... ......... .........
由上可知,generate 协程、map 协程、reduce 协程都正常结束了,main 主协程保持运行,功能正常。但假设 map 操作中途报错了,需要终止整个 mapreduce 操作,应该怎么做呢?初代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 func main () source := make (chan int ) collector := make (chan int ) var res []int go func () defer fmt.Println("generate end" ) defer close (source) arr := []int {1 , 2 , 3 , 4 , 5 } for _, v := range arr { source <- v } }() go func () defer fmt.Println("map end" ) var wg sync.WaitGroup defer func () wg.Wait() close (collector) }() count := 0 for v := range source { count++ if count == 4 { return } wg.Add(1 ) go func (item int ) defer wg.Done() collector <- item + 100 }(v) } }() go func () defer fmt.Println("reduce end" ) for v := range collector { res = append (res, v) } }() for { fmt.Println("result:" , res, ", goroutine num:" , runtime.NumGoroutine()) time.Sleep(time.Second) } }
运行结果:
1 2 3 4 5 6 7 8 9 10 result: [] , goroutine num: 4 reduce end map end result: [101 103 102] , goroutine num: 2 result: [101 103 102] , goroutine num: 2 result: [101 103 102] , goroutine num: 2 result: [101 103 102] , goroutine num: 2 ......... ......... .........
从结果可知,还是出现了协程泄漏的问题,这是因为 generate 协程不知道 map 协程因为出错结束了,所以要解决这个问题就是另外一句话:谁接收谁消费殆尽 。只需要将 generate 协程消耗殆尽就行了,优化代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 func main () source := make (chan int ) collector := make (chan int ) var res []int go func () defer fmt.Println("generate end" ) defer close (source) arr := []int {1 , 2 , 3 , 4 , 5 } for _, v := range arr { source <- v } }() go func () defer fmt.Println("map end" ) var wg sync.WaitGroup defer func () for range source { } wg.Wait() close (collector) }() count := 0 for v := range source { count++ if count == 4 { return } wg.Add(1 ) go func (item int ) defer wg.Done() collector <- item + 100 }(v) } }() go func () defer fmt.Println("reduce end" ) for v := range collector { res = append (res, v) } }() for { fmt.Println("result:" , res, ", goroutine num:" , runtime.NumGoroutine()) time.Sleep(time.Second) } }
运行结果:
1 2 3 4 5 6 7 8 9 10 11 result: [] , goroutine num: 4 generate end reduce end map end result: [102 101 103] , goroutine num: 1 result: [102 101 103] , goroutine num: 1 result: [102 101 103] , goroutine num: 1 result: [102 101 103] , goroutine num: 1 ......... ......... .........
因此针对通道导致的协程泄漏,只要记住 谁写入谁关闭,谁接收谁消费殆尽 基本就不会出大问题。
将通道数据消耗殆尽的操作字 go-zero 封装成了一个函数
1 2 3 4 5 func drain (channel <-chan interface {}) for range channel { } }
回归到 cancel 函数的设计,由于该函数的目的是接收一个错误,然后进行取消操作,我们可以定义函数为 cancel(err error) ,并且该函数只能被执行一次,因为涉及到 close 通道,多次 close 通道会导致 panic ,所以可以使用 sync.Once 解决这个问题。通过定义函数 func once(fn func(error)) func(error) 和使用闭包进行封装,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 func once (fn func (error) ) func (error) once := new (sync.Once) return func (err error) once.Do(func () fn(err) }) } } cancel := once(func (err error) if err != nil { retErr.Set(err) } else { retErr.Set(ErrCancelWithNil) } drain(source) finish() })
在 map 和 reduce 代码设计部分提到一个为了广播结束事件的通道 done,这个通道也不能被 close 多次,go-zero 针对这种广播结束事件的通道也进行了一次封装,同样使用的是 sync.Once ,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 type DoneChan struct { done chan struct {} once sync.Once } func NewDoneChan () *DoneChan return &DoneChan{ done: make (chan struct {}), } } func (dc *DoneChan) Close () dc.once.Do(func () close (dc.done) }) } func (dc *DoneChan) Done () chan struct return dc.done }
在 finish 函数中主要就是关闭通道 done,因此代码为:
1 2 3 finish := func () done.Close() }
代码块组合 至此,我们可以将上面讲的各个部分的代码块进行组合,获得我们最终的 MapReduce 函数,代码如下:
1 2 3 4 func MapReduce (generate GenerateFunc, mapper MapperFunc, reducer ReducerFunc, workers int ) (interface {}, error) source := buildSource(generate) return MapReduceWithSource(source, mapper, reducer, workers) }
其中,generate GenerateFunc ,mapper MapperFunc,reducer ReducerFunc 三部分都交给使用者去实现,workers 是控制的协程数量(此处源码是用 FUNCTIONAL OPTIONS 函数式编程方式,由于不是本文重点,因此直接用整型)。核心代码就是 MapReduceWithSource(source, mapper, reducer, workers) ,实现方式如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 func MapReduceWithSource (source <-chan interface {}, mapper MapperFunc, reducer ReducerFunc, workers int ) (interface {}, error) output := make (chan interface {}) collector := make (chan interface {}, workers) done := syncx.NewDoneChan() writer := newGuardedWriter(output, done.Done()) var closeOnce sync.Once var retErr errorx.AtomicError finish := func () closeOnce.Do(func () done.Close() close (output) }) } cancel := once(func (err error) if err != nil { retErr.Set(err) } else { retErr.Set(ErrCancelWithNil) } drain(source) finish() }) go func () defer func () drain(collector) if r := recover (); r != nil { cancel(fmt.Errorf("%v" , r)) } else { finish() } }() reducer(collector, writer, cancel) }() go executeMappers(func (item interface {}, w Writer) mapper(item, w, cancel) }, source, collector, done.Done(), options.workers) value, ok := <-output if err := retErr.Load(); err != nil { return nil , err } else if ok { return value, nil } else { return nil , ErrReduceNoOutput } }
总结 本文对 go-zero 中的 MapReduce 代码进行了拆解分析,代码还是比较简练易懂,对通道的使用也是值得学习的,简要概括如下:
通道的使用遵循”谁写入谁关闭,谁接收谁消费殆尽“,要小心协程泄漏
利用 close 通道达到广播通知的效果
使用 sync.Once 保护部分只能执行一次的代码
注意对 panic 进行 recover ,为使用者兜底